はじめに
リアルワールドデータを使ったデータベース研究において、エンジニアとのコミュニケーションがうまくいかない、という話をよく聞きます。そういった時には、双方がお互いの分野・業務内容を理解し、良い連携の仕組み・コミュニケーションの方法を確立させることで協働がスムーズになります。
本記事では、非エンジニアがSQL・データベースの基礎を知ることを目的としています。データベース研究におけるデータエンジニアの役割から、実行したい指示がどのようなSQLに変換されるのかの実例を紹介します。
データベース研究におけるデータエンジニアの役割
データベース研究においてデータエンジニアがどのようなプロセスで活躍しているのか、ご存知でしょうか。データエンジニアの役割、必要性について紹介します。
データベース研究におけるデータエンジニアの役割
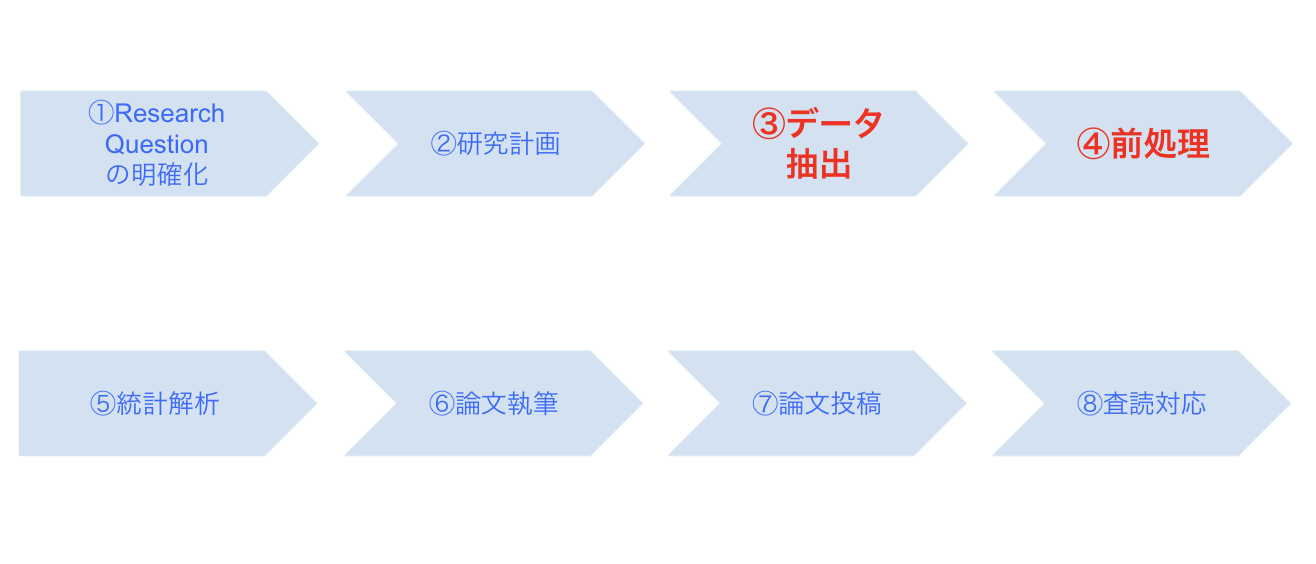
上図がデータベース研究の流れです。特にデータエンジニアが活躍するのは「データ抽出」と「前処理」です。
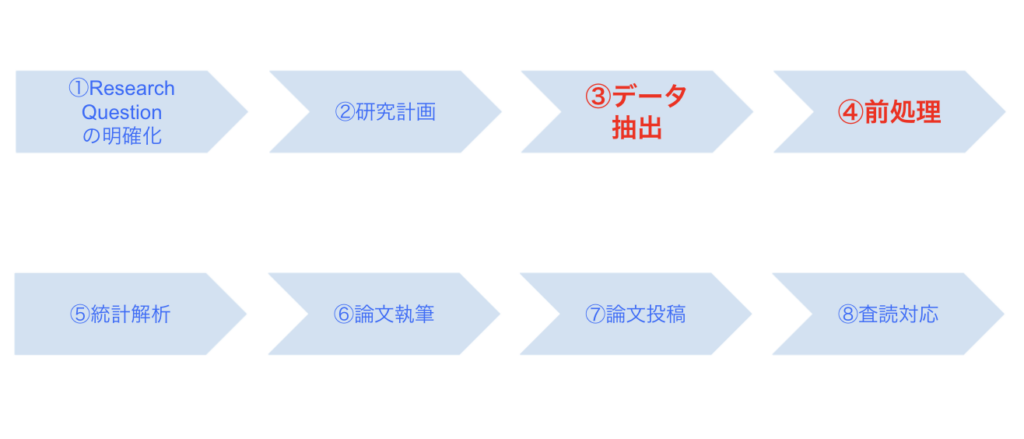
データベース研究における重要なプレイヤーである臨床疫学者、臨床専門家とデータエンジニアの役割分担を示した図が下記です。
臨床疫学者、臨床専門家、データエンジニアの間では、密な連携・コミュニケーションが必要です。
なぜなら、
- 臨床疫学者が作った解析計画書の通りデータを抽出したけど、対象患者がほとんどいなかった。
- 指示されたコードでアウトカムを定義したが、全然なかった。
ということがよく起きるからです。
データ抽出と前処理が必要な理由
では、データエンジニアが活躍する「データ抽出」と「前処理」の工程はなぜ必要なのでしょうか。2つの工程が必要な理由と意義を説明します。
| 必要な理由 | 意義 | |
| データ抽出 | データが大きいと処理に時間がかかる、 あるいは処理できない | 必要なデータに絞り、小さくすることで 扱いやすくなる |
| 前処理 | リアルワールドデータには不正確なデータや 無関係なデータが混じっているから | データを綺麗にして、取り扱いやすくする |
このような処理を行うことで、後の工程(例えば統計解析)がスムーズに行えるようになり、ミスも減ります。
前処理で何を行うのか?
前処理は、データクリーニング・データクレンジングとも呼ばれます。実際に何をするのかイメージがつかないかもしれないので、どのような処理を行うのか、具体的に説明します。
- 不正確なデータの除外や修正
- 尿定性の列に尿定量の値が混じっている、レセプト電算コードに無効な値がはいっているなど、様々なエラーが存在します。状況に応じて、除外や修正を行います。
- 重複の除外
- 何らかの理由で同じレコードが存在してることがあります。全く同じレコードであれば、除外する必要があります。
- データの整形
- 100列以上あるようなデータは複数のテーブルに分ける、横持ちのデータを縦持ちに変えるなど、利用しやすい形に整えます。(「横持ち」と「縦持ち」のデータについては以前の記事『NDBオープンデータでみる生物学的製剤使用量の地域差』を参照ください。)
- 重要なデータの特定
- 生データには非常に多くの情報(列)が含まれていますが、その多くは有用ではありません。利活用を目的として重要な列を特定し、整理する必要があります。
- データの欠損の確認
- 有用そうな列があっても、実際にデータを触るとほとんど空白で使えないことがあります。研究の実現性に関わるため、必ず確認する必要があります。欠損が多い場合は、他に使える似たような列があるか探すか、あるいはリサーチクエスチョンや研究計画の変更を検討します。
- データの標準化
- 例えば検査値は医療機関によって検査会社や測定方法が異なるため、標準化が必要です。レセプトでは診療科も標準化が必要な項目です。
- マスタの紐付け
- 医薬品マスタ、ATCマスタ、ICD10マスタを紐付けることで、利用しやすくなります。
商用データベースの場合は、上記の前処理の多くを実施していることが多く、前処理の負担は減ります。一方で医療機関や保険組合から受領したデータを用いる場合、NDB(ナショナルデータベース)を用いる場合には、上記の前処理に膨大な工数が必要となります。もし利用を検討されている方はご注意ください。
SQL・データベースとは
皆さんもよく耳にするSQLについて解説します。
SQLとは?
SQLとはデータベース言語の1つで、データベースの定義や操作を行えます。
SQL及びデータベースの種類は非常に多く、代表的なものとして下記があります。
- Oracle Database(Oracle社)
- Microsoft SQL ServerやAccess(Microsoft社)
- MySQL
- PostgreSQL
- SQLite
SQLの種類は多いですが、基本的な構文は同じです。1種類のSQLを習得すれば、他のSQLでもドキュメントを見ながら操作できます。
具体的にはSQLを使うことで、データベースに対して下記の操作を行います。
- データの検索
- データの追加
- データの更新
- データの削除
- テーブルの作成
- テーブルの削除
- テーブルの主キーの設定
- ユーザー権限の付与
データベース研究における身近な処理として用いるのは「データの検索(SELECT)」です。ここから先は「データの検索(SELECT)」に絞ってお話します。
データベース構造例
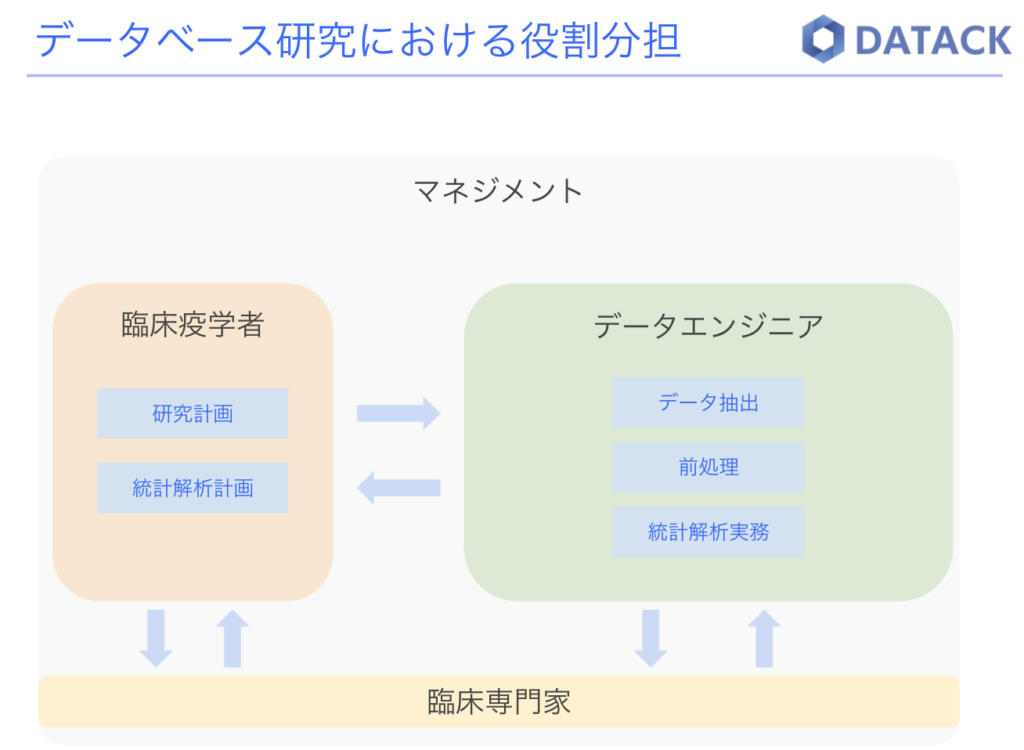
レセプト情報を想定して、簡単なデータベース構造のサンプルを作成しました。
「患者情報」「傷病名」「診療行為」「医薬品」という4つのテーブルがあります。各テーブルに記載されているのが、列です。黄色で強調されているのは、各テーブルの主キーです。主キーはテーブル内でユニークであり、重複や欠損を許しません。そのため主キーを通じて、テーブル内のレコードを一意に識別することが出来ます。実際主キーという概念がないcsvファイルやexcelファイルでは、一意であるはずの患者IDが重複していたり欠損していたりして処理に困ることがあります。
「患者ID」という列は全テーブルに存在し、線で結ばれています。もし複数のテーブルにまたがった情報が必要な場合、共通の列で結合して利用します。
SQLの基本的な構造
データの検索で使う基本的な構造を下記に記します。
| SELECT <必要な列名(複数選択可)> FROM <抽出したいテーブル名> WHERE <抽出したい条件> |
データベースは複数のテーブルから成るため、FROM句でテーブルを指定し、WHERE句で抽出条件を指定し、SELECT句に必要な列を明示します。
実行したい指示とSQLサンプル
先程紹介したレセプト情報のデータベースを用いて、実行したい指示に対してどのようなSQLに変換されるのかを紹介します。
今回紹介するのは、SQLを用いた集計とデータ抽出の2種類です。
サンプル①: 数の集計
| やりたいこと2020年に心房細動と診断された18歳以上の患者の数を知りたい |
まず心房細動を指定するためのコードを調べる必要があります。
心房細動のICD-10コードは、I48です。
| I480 | 発作性心房細動 |
| I481 | 持続性心房細動 |
| I482 | 慢性心房細動 |
| I483 | 定型心房粗動 |
| I484 | 非定型心房粗動 |
| I489 | 心房細動及び心房粗動,詳細不明 |
このコードを用いて、SQL文を作成します。
| SELECT COUNT(DISTINCT 患者ID) FROM 患者情報 INNER JOIN 傷病名 ON 患者ID WHERE 患者情報.生年月 < 200103 AND 傷病名.ICD10 = I48 |
実行時間は50秒で、542名という結果が得られました。
しかし抽出後に、疑い病名は除外したかったことに気づきました。このように指示後の確認やディスカッションを通じて修正することは頻繁に起きるので、臨床疫学者や臨床専門家による確認・ディスカッションが大切です。
次のサンプルSQLでその修正を行います。
サンプル②: 数の集計(条件を追加)
| やりたいこと2020年に心房細動(疑い病名は除く)と診断された18歳以上の患者の数を知りたい |
ICD-10コードは先程と同様に、I48を用います。
WHERE句に疑いフラグが0(疑い病名ではなく、確定病名である)という条件を1つ追加します。
| SELECT COUNT(DISTINCT 患者ID) FROM 患者情報 INNER JOIN 傷病名 ON 患者ID WHERE 患者情報.生年月 < 200103 AND 傷病名.ICD10 = I48 AND 疑いフラグ = 0 |
実行時間は50秒のままで、抽出結果は305名でした。
対象患者数は少なくなってしまいました。
サンプル③: データセット抽出
続いて、データセットの抽出を行います。
大きなデータセットから必要なデータに絞り込むことで、手元で取り扱いやすくなります。
| やりたいこと2020年に心房細動と診断された18歳以上の患者に使われている医薬品データを欲しい |
| SELECT 患者ID, 診療年月, 販売名, 一般名, 投与量, 投与日数, 点数 FROM 医薬品 WHERE 患者ID IN ( SELECT (DISTINCT 患者ID) FROM 患者情報 INNER JOIN 傷病名 ON 患者ID WHERE 患者情報.生年月 < 200103 AND 傷病名.ICD10 = I48) |
少し複雑なSQL文になりました。
実行時間は94秒です。先程の305名のうち、2名はなぜか医薬品テーブルにデータが欠損していたため、303名分の医薬品データセットを抽出できました。
最後に
データベース研究におけるデータエンジニアの役割からSQL・データベースの基礎、SQLの具体例を紹介しました。特に最後のSQL具体例を通じて、私たちの思考は曖昧なことが多く、SQLに落とし込むためには細かい定義を決める必要があること・SQLに変換すると複雑になることを実感できたのではないでしょうか。
データエンジニアと上手くコミュニケーションをとるためには、コードや期間の指定など曖昧さを残さず明確にすることが大切です。もし興味を持った方は、是非SQLを勉強してみてください。
※データックでは、SQLに関するご相談を受け付けております。お問い合わせフォームよりお気軽にご連絡ください。
